プラントデータ、シミュレーションデータの取り扱い
このページではプラントの生データの前処理や解釈、シミュレーションへのデータ入力や結果解釈等についてまとめていきます。 数理モデリングの本質について、いくつか私の好きな表現を紹介します。Rutherford Aris は化学工学における数理モデルの考え方を体系的にまとめています(例:『Mathematical Modeling: A Chemical Engineer’s Perspective』)。「モデルとは物理システムを適切に記述する数学方程式の集合である」という整理がされています。 J.-M. Marin & C.P. Robert 著『Bayesian Essentials with R』によれば、モデルは現実の現象をある程度の近似で解釈する「物語」であり、必ずしも唯一の「真実」である必要はありませんが、実用的な精度で予測できる必要があると述べられており、化学工学の思想をよく現わしていると感じます。 また、「統計学は、膨大なデータの断片から重要なパターンやトレンドを抽出し、健全な意思決定を可能にする情報へと変換する学問」と表現されていますが、この表現も化学工学と統計学の相性の良さを示しているなと感じます(例:James ほか『An Introduction to Statistical Learning』の位置づけ)。
データの収集
データの収集について▼
データ処理の練習をする上で、練習用のデータをどうやって用意するかという問題があります。プラントの生データにアクセスすることができればベストですが、生データが無い場合、仮想のデータセットを用意する上でいくつかのアプローチがあるかと思います。以下、いくつかの方法をご紹介します。
Kaggleでは公開データセットをAPI経由で取得でき、実務に近い時系列解析の練習が可能です。また、UCI Machine Learning Repository などには、分類・回帰用の古典的データセット(例:Soybean など)が公開されています。手書き文字や画像に近い題材では別リポジトリのデータセットを参照する場合もあります。これらを用いることで、欠損補完や外れ値処理といった前処理の反復練習が可能です。
Driven Data(Pump It Up コンペ)、FRED等。さらに、G. James らの著書『An Introduction to Statistical Learning』に付随する `ISLR` パッケージには、`Smarket`(市場データ)や `Auto`(車両燃費)、`College`(大学データ)といった、統計学習の基礎を学ぶための良質な実例が含まれています。
回帰計算
ExcelのソルバーやPythonの最適化を使った回帰計算例、回帰計算の注意点等を整理していきます。 D. Ruppert 著『Statistics and Data Analysis for Financial Engineering』で引用されている Yogi Berra の言葉通り、「見るだけで、多くのことがわかる」ため、データ解析の第一歩は常に可視化になります。 R.M. Heiberger & B. Holland 著『Statistical Analysis and Data Display』で強調されていますが、適切なグラフは統計分析の心臓部であり、数値結果はそれを形式的に確認するための手段に過ぎないと言い切れます。
シンプルな回帰計算▼
単回帰は \(y=\beta_0+\beta_1x+\varepsilon\) の形で、最小二乗法により係数を推定します。例えば「リボイラーの蒸気流量 \(x\)」と「塔底温度 \(y\)」の関係など、物理的な相関を定量化します。解析前には、F.M. Dekking らの『A Modern Introduction to Probability and Statistics』にある通り、`stem-and-leaf`(茎葉図)や散布図で分布を確認し、変数間の直線性が期待できるかを確認します。例えば、蒸留塔における還流比と必要理論段数の関係のように、還流比を大きくするほど必要段数は減る一方で、単純な反比例ではなく曲線的な曲がりを示すことが多く、そのような場合は単純な直線近似が適切かどうかの判断が必要になります。
説明変数が複数ある場合、最小二乗法(OLS)が適用されます。実データでは説明変数同士の相関(多重共線性:Collinearity)がモデルを不安定にするため、慎重な診断が必要です。
- 多重共線性の具体例(冗長な収支・温度): 単純化した例として、反応器出口のモル流量 \(F\) [kmol/h] と質量流量 \(\dot m\) [kg/h] を、平均分子量 \(M=42.0\) [kg/kmol] が一定と分かっているときに両方説明変数に入れると、データ上は \(\dot m \approx M\,F\)(例:\(F=2.50\) のとき \(\dot m\approx 105\))となり、実質は同一情報の二重取り込みです。係数の推定分散が肥大化しやすいので、通常は \(F\) か \(\dot m\) のどちらか一方に落とします。
- 具体例(線形従属の制約式): 3 流路の合流点で、測定値が \(F_A=10.0\)、\(F_B=25.0\)、\(F_C=35.2\) [t/h] のとき、保存則から \(F_C\approx F_A+F_B\) が期待されます。\(F_A,F_B,F_C\) を独立な説明変数として回帰に入れると、ノイズの乗り方次第で係数が振れやすくなります(データレコンで先に整合させる、あるいは \(F_C\) を落とす等)。
- VIF(分散膨張係数)による確認: VIF は「その変数が他変数の線形結合でどれだけ説明されるか」の目安です。目安として VIF > 4(厳しめなら > 10)は再検討のサインで、上のような冗長ペアや従属流量を整理してから回帰するのが定石です。
主成分分析(PCA)は、相関の強い多数の変数を、互いに無相関な少数の直交成分へ圧縮する「データ削減」手法です。得られた軸は、元データのレベル(全体の高さ・強さ)、形(空間方向・波長方向のパターン差)、あるいは安全性や環境負荷といった複合指標の相対位置など、物理的に解釈しやすい要約になります。
- 数千の遺伝子データからの「がん型」特定: 製薬・バイオ分野では、NCI60 細胞株のように数千個の遺伝子発現量が一度に得られる巨大データセットがあります。これらを PCA で 2〜3 次元に圧縮して散布図にすると、細胞診などの事前ラベルなしでも、グラフ上で白血病・結腸がんなど組織タイプごとのクラスタが自然に分離して現れることがあります。次元を落とすことでノイズを削ぎ、がんの本質的な生物学的特徴(「正体」)を浮き彫りにする探索が可能になります。
参照元:G. James ほか An Introduction to Statistical Learning(2013) 第 10 章。
- サプライチェーン設計における環境目標の削減: 化学物質の供給網設計では、NPV による経済性のレベルを最大化しつつ、「生態系へのダメージ」「人間の健康への影響」「資源枯渇」など複数の環境指標を同時に扱うことがあります。指標が多すぎると、パレート面上のトレードオフの形が見えにくく意思決定が困難になります。PCA で環境指標間の相関を分析し、挙動が似ている冗長な環境目標を特定・統合して次元を下げることで、残すべきリスク・環境負荷の物理的意味を保ったまま意思決定プロセスを簡略化できます。
参照元:Pozo ほか (2012)/G. P. Rangaiah, C. L. Bonilla-Petriciolet 編 Multi-Objective Optimization in Chemical Engineering: Developments and Applications(Wiley, 2013) 第 3 章。 - プロセスルートの「本質的な安全性」の比較(IBI 指標): 火災・爆発・毒性・圧力など、安全性は多面的な指標に分かれがちで、案同士を一枚の尺度で並べにくいです。これらを PCA で圧縮し、本質的無害性指標(IBI: Inherent Benign-ness Indicator)のような少数の合成軸を構成すると、各プロセス案の総合的な安全レベルを直感的に比較でき、経済性とのトレードオフ検討がしやすくなります。
参照元:R. Srinivasan & T. A. Nhan (2008)/上記 Multi-Objective Optimization in Chemical Engineering: Developments and Applications(2013)第 16 章。 - グリッド探索の効率化(主成分グリッド・PCGA): PI コントローラのゲイン調整など、多変数最適化で入力空間を格子状に走査するグリッド探索(GSA)では、次元が上がると試行点が爆発しやすいです。パレート解が分布する狭い領域の幾何(向きと広がり)に合わせて PCA で座標を回し、その主構造に沿った新しい格子を張る(主成分グリッド・PCGA)ことで、計算時間を抑えつつ探索領域の近似精度を高められます。
参照元:A. Vandervoort (2010)/上記 Multi-Objective Optimization in Chemical Engineering: Developments and Applications(2013)第 17 章。
プラント工学では、多段温度プロファイルや近赤外の多波長スペクトルでも同様に、第 1 主成分が全体のレベル(オフセット)、続く成分が塔高方向・波長方向の形(傾き・曲率)の違いを表しやすく、濃度推定などソフトセンサーへの前処理として広く用いられます。
因子分析は、観測変数の背後にある「潜在因子(Common factors)」を推定します。プラント内の多数の温度計が同時に変動している場合、それらの背後に「外気温の影響」や「原料供給負荷の変動」といった共通の物理的要因(因子)を想定し、各センサーがどの因子にどれだけ影響を受けているかを特定できます。
クラスタリング▼
クラスタリングは、ラベルなしデータを類似性に基づいて自動分類する手法です。K-means法などが代表的ですが、外れ値に対する堅牢性を高めるために K-medoids 法なども検討されます。
scikit-learn の OPTICS を使って、以下の仮想プラントデータをロード毎に分類していきます。OPTICSは密度ベースの手法であり、DBSCANの弱点であった「密度の異なるクラスタ」の検出を改善しており、境界が曖昧なプロセスデータにおいても、正常な運転モードとそこから逸脱した異常値を分離するのに適しています。
NRTLのbinary parameterのRegression例▼
実用的な回帰計算例として、バイナリーパラメーターの回帰計算例をご紹介します。違いを見やすくするために、ほぼ理想状態のバイナリーパラメーターからスタートし、水-エタノールの回帰を行います。
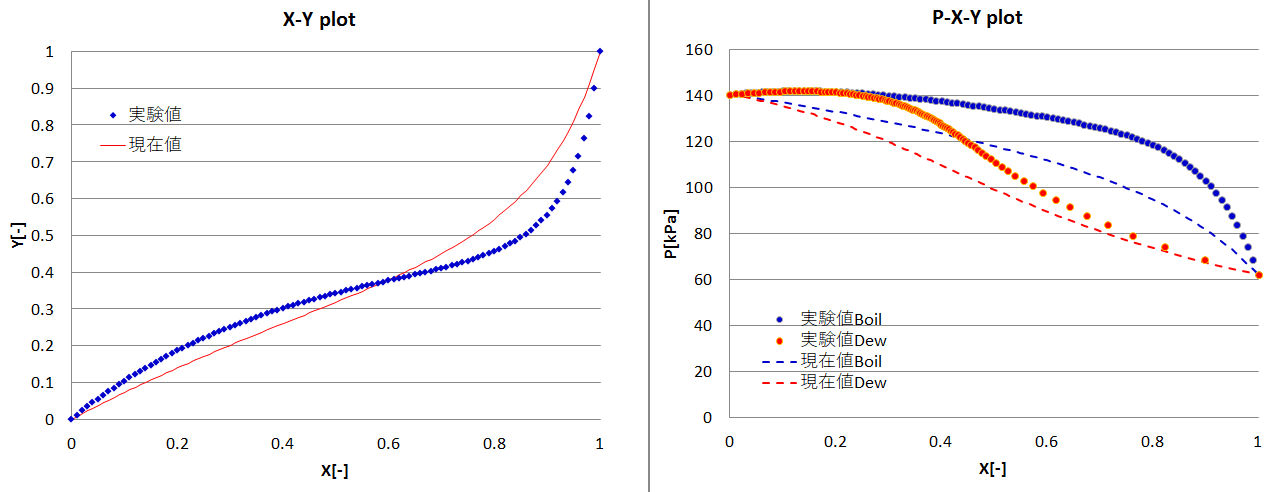
実験データと計算上の値との自乗誤差を積算し、誤差が最小となるパラメーターをExcelのソルバーで求めます。Excelのようなポイント・アンド・クリック技術は日常的なタスクには便利ですが、非常に非線形性が強い問題では、浮動小数点演算の精度を考慮したスクリプトベースの制御が望ましい場合もあります。
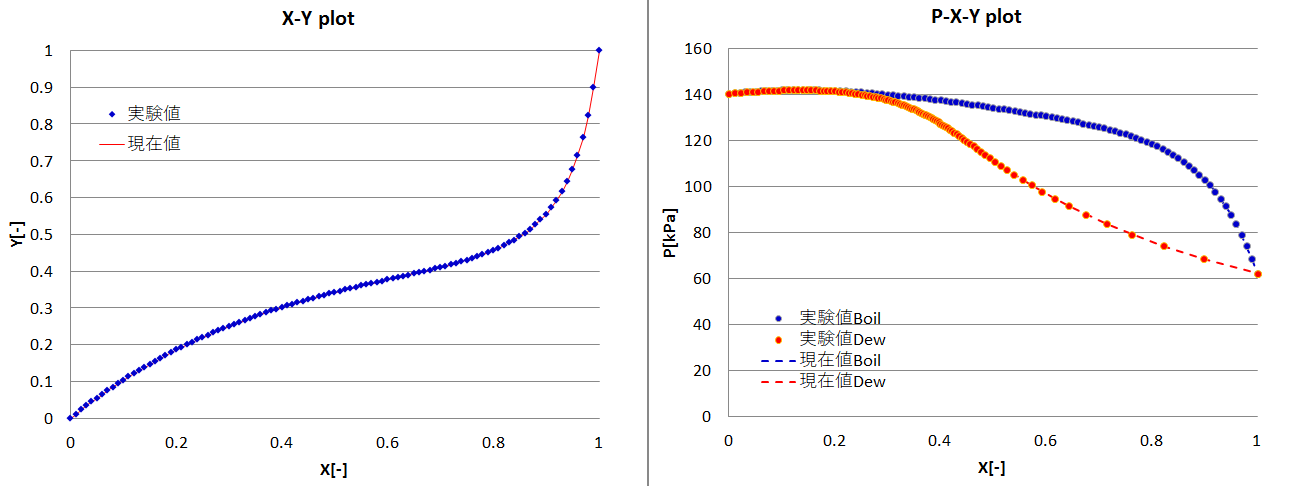
以下はwater-methanolの例になります。
(NRTLの詳細については、こちらを参照ください)
scipy.optimizeのleastsqやcurve_fitを使っていきます。非線形回帰では初期値(Start value)の設定が極めて重要であり、誤った初期値は収束の失敗や「局所解」に陥るリスクを高めます。
回帰計算時の注意点▼
回帰計算を行う前には、必ずデータを可視化すべきです。アンスコムの例は、平均や相関といった統計数値が同一であっても、グラフにすると直線、曲線、外れ値の影響など、全く異なる物理的事象が含まれていることを示す非常に重要な警告です。
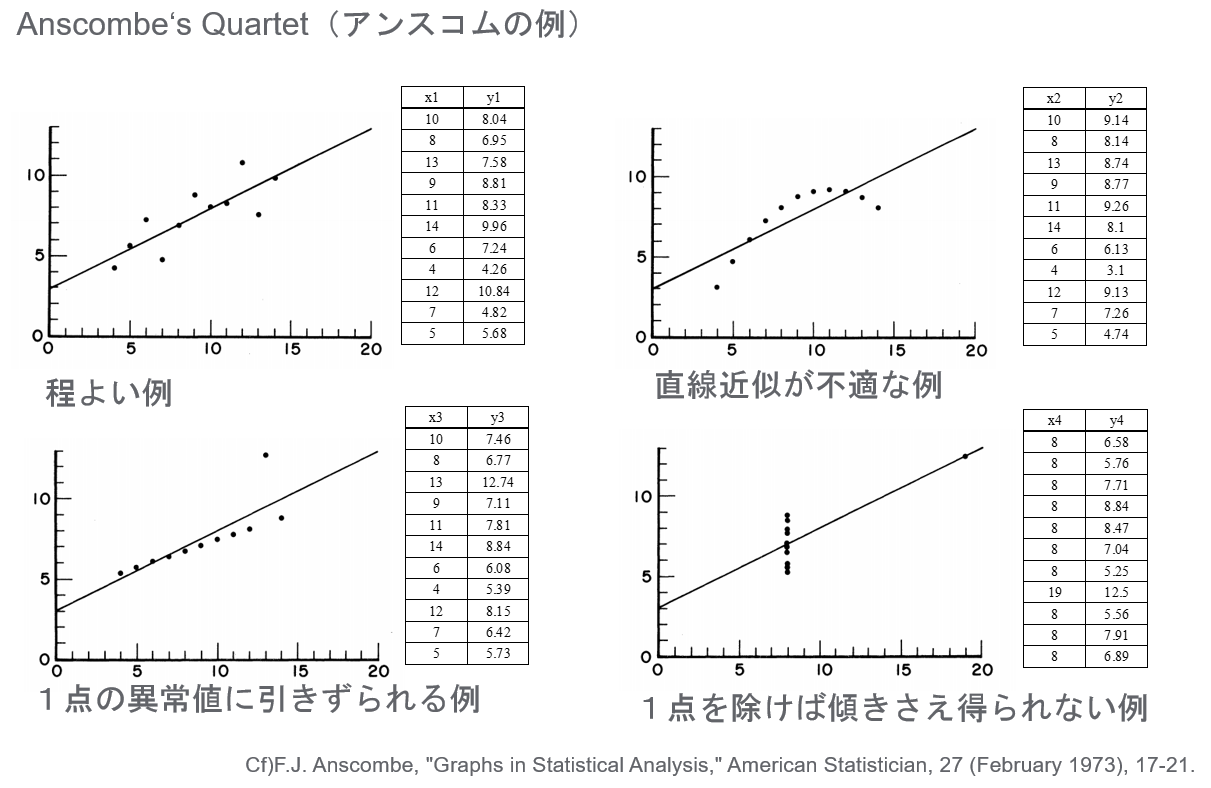
こちらの本が非常に参考になります。
アンスコムの例も紹介されていますが、他にも回帰をする上での注意点が分かりやすくまとめられています。
他にもあり勝ちな問題として「過学習(Over-fitting)」があります。誤差を最小化するために次数の高すぎる多項式を用いると、訓練データには完璧に適合しますが、新しいデータ(テストセット)に対しては予測精度が著しく低下します。これを避けるには、パラメータ数を抑える「パルシモニー」の原則や、Lassoなどの正則化手法が推奨されます。
ツールの活用▼
物性の回帰については、なかなか初期値が悪いと収束しないケースもあります。そうした場合、強力なツールとしてDechemaの出しているDPPがあります。複数の最適化アルゴリズムを搭載しており、実験データの信頼性に基づいた「重み付け回帰」を行うことで、ロバストなパラメータ推定が可能となります。
シミュレーション前のデータ処理
プロセスシミュレーションを行う前に、整合性の取れたデータ(Consistent data)を準備することが極めて重要です。
定常データに対するData Reconciliation▼
プラントの計器データは、ノイズや計器故障(Gross Error)を含んでおり、そのままでは物質・熱収支(Mass/Heat Balance)が成立していません。定常シミュレーターにそのまま生値を流し込むと、収支不一致のため収束しない、あるいは物理的に不可能な解を導く原因となります。Data Reconciliation は、物理法則(収支制約式)を満足しつつ、統計的に最も確からしい「真の値」を推定するプロセスです。
計器ごとの精度(分散の逆数)に基づいて重み付けを行い、測定値と推定値の偏差の二乗和を最小化します。信頼性の高い流量計の値を尊重しつつ、分析誤差の大きい組成値を調整することで、プラント全体の整合性を回復させます。
最近のトレンド
近年は、データをきれいに整えるだけでなく、品質の継続監視、因果推論、デジタルツイン、AI 支援の分析まで含めて設計することが重要になっています。以下では、実務で特に注目されている論点を追加で整理します。
データ品質とデータ観測性
近年のデータ処理では、欠損値の補完や外れ値の除去に加えて、データの信頼性を継続的に監視するデータ観測性(data observability)が重視されています。具体的には、鮮度、件数、分布の変化、スキーマの変更、異常検知などをパイプライン上で追跡し、ダッシュボードや機械学習モデルの手前で問題を早期に発見する運用が広がっています。
AI 活用が進むほど、推論そのものの正しさだけでなく、「壊れたデータをいかに早く見つけるか」がボトルネックになりやすくなります。そのため、データ品質は後付けの清掃作業ではなく、取り込み・変換・特徴量作成までを含むパイプライン全体の基盤機能として組み込むのが自然です。
計器誤差のタイプ▼
計器誤差は大きく、ゼロ付近にランダムに分布する誤差と、系統的な偏りを持つ誤差に分けられます。
Random Error偶然誤差であり、通常は正規分布を仮定して最小二乗法で処理されます。移動平均等による平滑化(Smoothing)が有効です。
Gross Error計器故障やバルブの漏れなど。これらは通常の最小二乗法では吸収できないため、まずは異常検出(GED)によって特定し、モデルから除外または別モデル化する必要があります。
計器誤差のフィルタリング▼
生データからノイズを除去し、プロセス信号を抽出します。性能評価には、真の値との絶対誤差を積分する Integral Absolute Error (IAE) などが用いられます。
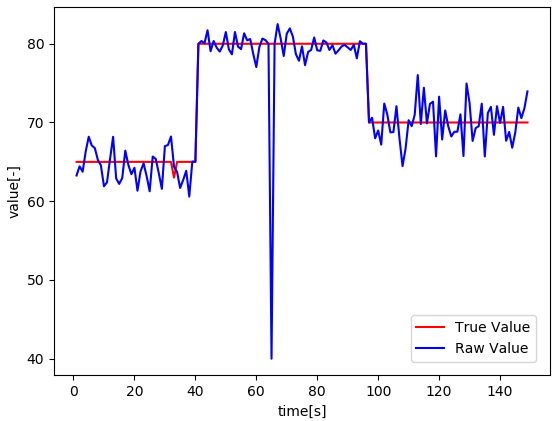 指数フィルタ
指数フィルタ
逐次的なデータ処理に適していますが、平滑化を強めるとプロセス変化に対する「時間遅れ(Delay)」が生じます。このトレードオフの評価が設計の鍵となります。
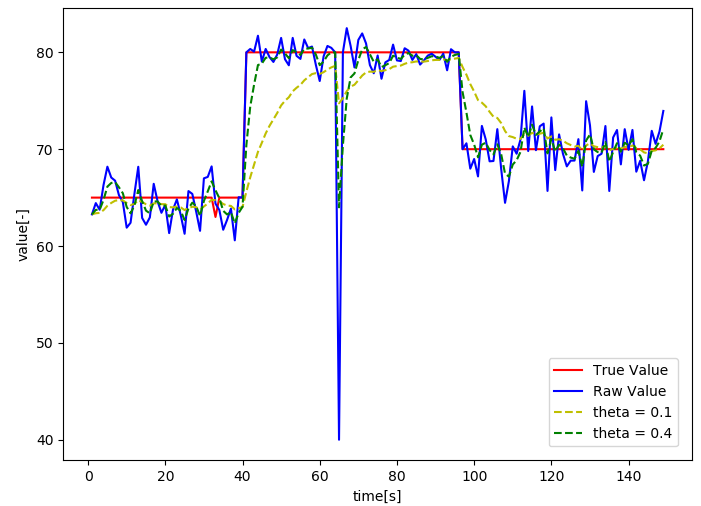 移動平均フィルタ
移動平均フィルタ
直近 N 点の平均を取る手法です。ノイズ除去には強力ですが、やはり時間遅れの発生が課題となります。A.F. Zuur らの著書『A Beginner's Guide to R』でも、複雑なデータセットを扱う際の基本的な「マッサージ」手法として紹介されています。
Xcos、Simulinkを使ったフィルタリング▼
ScilabのXcosでは `Rfile_f` を用いてデータを読み込みますが、Fortranフォーマットへの準拠が求められるなど、多様な入力形式への対応には工夫が必要です。
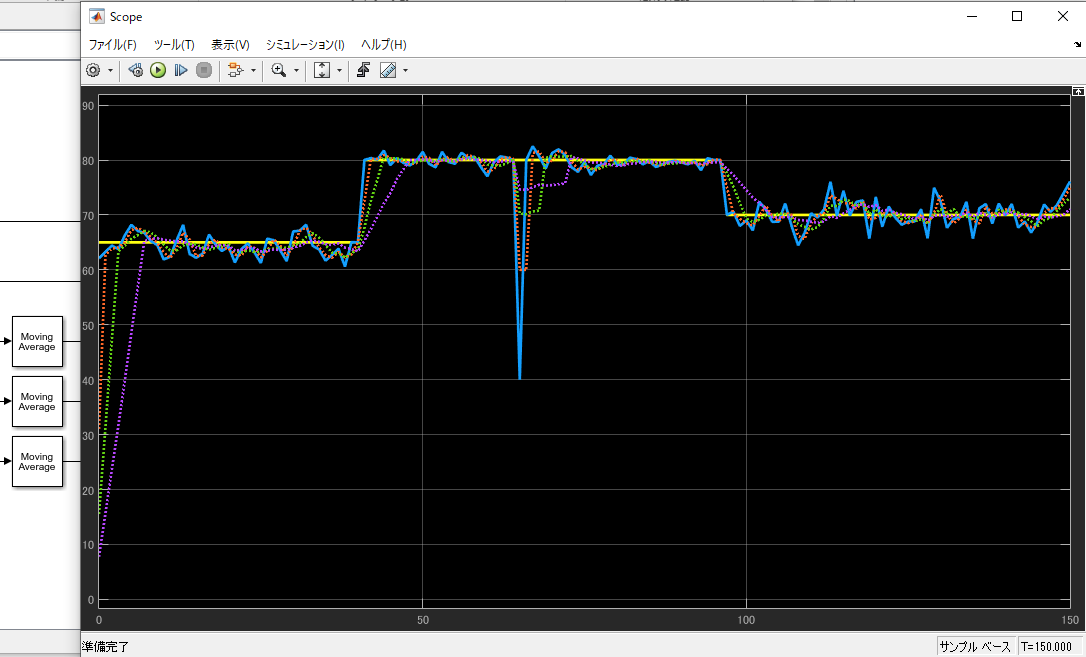
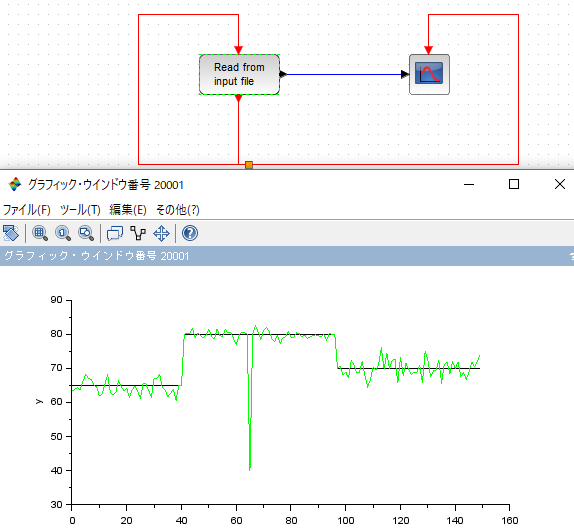 Simulink
Simulink
SimulinkはCSV等の多様な入力を直接サポートしており、GUI上でのモデル検証が極めて容易です。`DSP System Toolbox` を活用することで、様々なフィルタ(Moving Average等)の動的な振る舞いを直感的に比較検討できます。
シミュレーターを使ったData Reconciliation▼
現代のシミュレーター(AVEVA Process Simulation等)には、統合されたData Reconciliation機能が搭載されています。Transmitterモデルに誤差計算用のサブモデルを追加することで、物理法則に基づいた最適な推定がGUI上で完結します。
定常状態の判定▼
データレコンを行う前に、プラントが定常状態にあるかを判定する必要があります。単なる目視(Visual inspection)ではなく、分散の変化を評価するF検定や、平均の有意差を見るt検定(p値の算出)を時系列に適用することで、客観的な判定が可能になります。特に、p値が 0.05 を下回る場合は「有意な変化あり」と判断し、定常シミュレーションの前提が崩れているとみなします。
非定常データに対するData Reconciliation
真のデジタルツイン(Digital Twin)を実現するためには、過渡状態を含む動的なデータ処理が必要です。
非定常データに対するData Reconciliation▼
プラントは常に外乱や劣化の影響下にあるため、定常状態はむしろ例外です。動的なデータレコン(Dynamic Data Reconciliation)では、ホールドアップの変化を伴う微分方程式 \(\frac{dM}{dt}=F_{in}-F_{out}\) を制約条件に含め、過去の履歴と整合する軌道を推定します。Python では scipy.integrate.solve_ivp や従来の odeint などの ODE ソルバーを用いることで、蓄積項が無視できない状況での状態推定が可能になります。
デジタルツインと動的データ整合化
定常のデータレコンにとどまらず、時間変化を明示した動的データ整合化は、デジタルツインを支える重要な技術の一つです。センサー誤差、サンプリングのずれ、モデル構造の簡略化に由来する誤差を補正しながら、現実のプラント状態を時系列で一貫して推定する点に特徴があります。
近年のデジタルツインは、監視用の可視化にとどまらず、予測・最適化・自律的な判断まで含む実行基盤へと進化しています。製造やプロセス産業では、IoT、クラウド、AI/ML との統合が進み、実運用に近い形での導入事例も増えています。
ソフトセンサー
ソフトセンサー(Virtual analyzer)は、測定困難な指標(製品純度等)を、他の容易な測定値(温度、圧力等)からリアルタイムに推定する技術です。
因果推論と意思決定
回帰分析や相関分析は、変数がともに動く関係を捉えるのに有効です。一方、実務では「何を変えれば、どの結果がどれだけ変わるか」を知りたい場面が少なくありません。そのような問いに対応するのが、交絡(confounding)を考慮しながら介入効果や反実仮想(counterfactual)を扱う因果推論です。
近年は、因果推論を研究用途に限らず、説明可能で監査しやすい意思決定の枠組みとして位置づける流れが強まっています。ランダム化された A/B テストが難しいケースでも、観測データから因果効果を推定する手法の需要が高まっています。
ソフトセンサーの構築と課題▼
実データには、外れ値、時間遅れ、サンプリング間隔の不一致等が含まれます。変数のスケールを揃える標準化(Standardization)が、機械学習モデルの安定性に寄与します。特に `caret` パッケージを用いた `nearZeroVar`(近ゼロ分散変数の除去)などの前処理手順が実務上有効です 。
外れ値の検出
外れ値(Outlier)の特定には、3σルール、IQR法、あるいは `Isolation Forest` のような機械学習アルゴリズムが実用的です。例えば、ポンプの「嫌な音」に現れる微小な予兆(ベアリング摩耗等)を、多次元空間での仲間外れ検出によって捉えることが可能です。
欠損値の補完
欠損値(Missing values)は単に削除するのではなく、K-近傍法(KNN Imputation)や、F.E. Harrell 著『Regression Modeling Strategies』で推奨されている予測平均マッチング(PMM)を用いて、関連変数の情報から補完するのが現代的なアプローチです。
データ補完
実験値や性能曲線の隙間を埋めるための数値補間技術、特に物理的に自然な接続を得る手法について整理します。
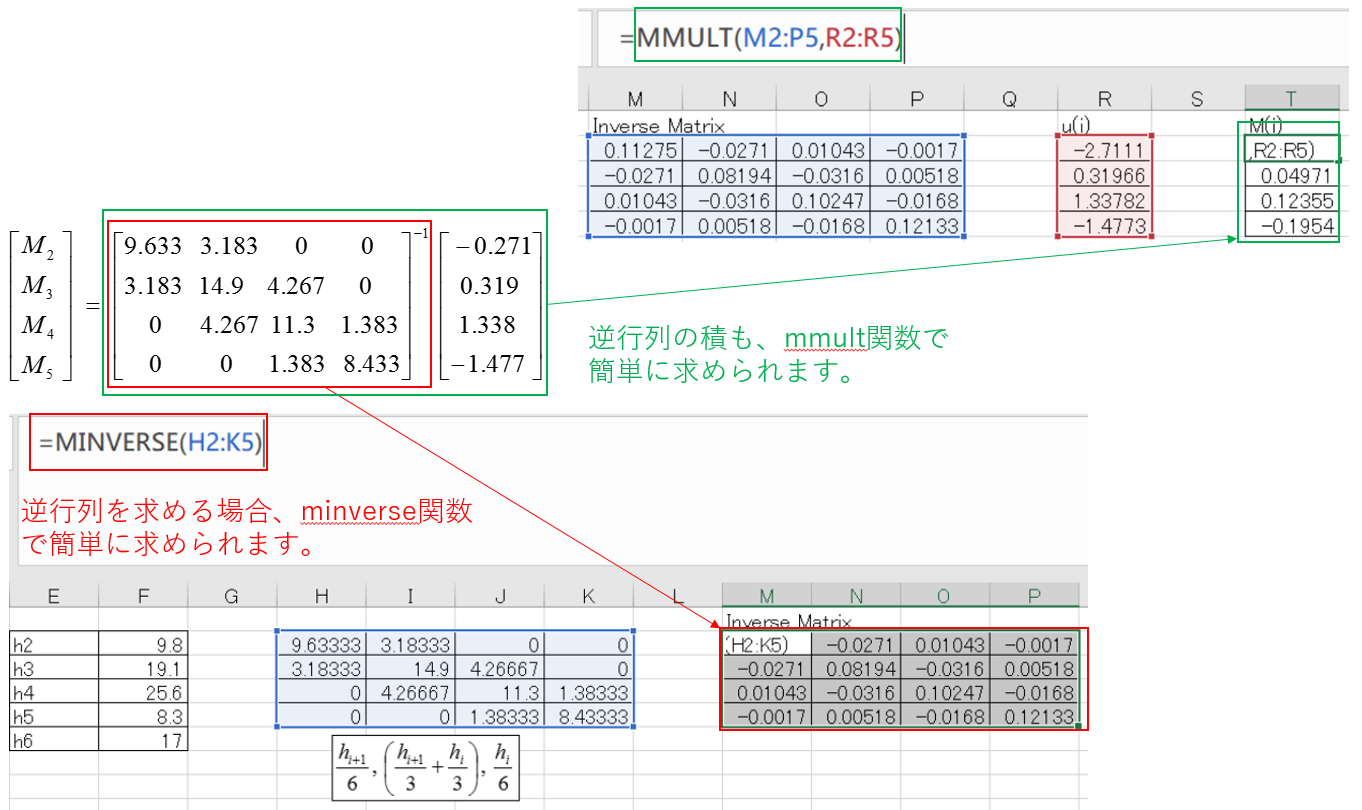
Cubic Spline▼
n個の点間を3次多項式で滑らかに接続します。接続点(Knot)において1次・2次導関数が連続になるように設定されるため、物理的に極めて自然な曲線(スプライン曲線)が得られます。特に両端の2次微分をゼロとする「ナチュラル」条件は、不自然なうねりを防ぐために広く採用されます。
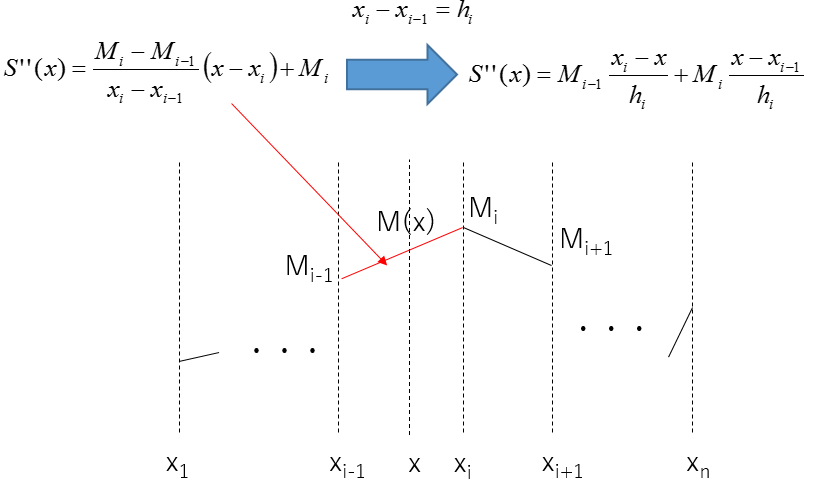
Pythonでは `scipy.interpolate.CubicSpline` を用いることで実装可能です。AVEVA Process Simulation などのシミュレーターには、画像データから性能曲線を自動生成する機能が搭載されています。
Excelでは `MINVERSE`(逆行列)と `MMULT`(行列積)を組み合わせることで、スプライン係数を直接算出できます。小規模なデータの素早い整理に有効です。
プロジェクト経済性評価 (NPV/IRR)
「技術的に可能」であることと「事業として儲かる」ことは別問題です。 投資判断の枠組み(割引キャッシュフロー、NPV/IRR 等)は統計の回帰とは別領域ですが、エンジニアリング提案には時間価値を踏まえた経済的裏付けが不可欠です。詳細は化工経済の専門書(例:Peters ほか『Plant Design and Economics for Chemical Engineers』)を参照してください。
回帰モデルの報告作法・予測モデルの注意点については、Harrell『Regression Modeling Strategies』のような文献が引き続き有効です。
投資評価の基本指標▼
プラントの改造や起業検討において、初期投資(CAPEX)が将来にわたってどれだけのキャッシュを生むかを評価します。ここでは割引率を \(r\)(例:年率 10% なら \(r=0.10\))、時刻 \(t\) 年目(\(t=0\) を投資の直後)の税引後フリー・キャッシュフローを \(CF_t\)、初期投資を \(I_0\) と書きます。
NPV(正味現在価値)は、将来キャッシュフローの現在価値の和から初期投資を引いた値です。
$$ \mathrm{NPV}(r) = -I_0 + \sum_{t=1}^{T} \frac{CF_t}{(1+r)^t} $$NPV が正なら、割引率 \(r\) の下では投資が価値を生む、という意味です(\(T\) は評価期間)。
IRR(内部収益率)は、NPV がゼロになる割引率 \(r^\*\) を解く問題として定義されます。
$$ 0 = -I_0 + \sum_{t=1}^{T} \frac{CF_t}{(1+r^\*)^t} $$得られた \(r^\*\) が会社のハードルレート(要求収益率)を上回るかどうかが、承認判断の一つの目安になります。
数値例(イメージ): \(I_0=100\)(百万円)、\(T=3\)、\(CF_1=40,\ CF_2=45,\ CF_3=50\) とします。割引率 \(r=10\%\) のとき
$$ \mathrm{NPV}(0.10) = -100 + \frac{40}{1.1} + \frac{45}{1.1^2} + \frac{50}{1.1^3} \approx 11.1 $$よってこの数字設定では NPV は正で、「年率 10% で割り引いても約 11 百万円の余剰価値」という読み方になります(税・運転費の内訳は実務で別表に分解します)。
Python では numpy_financial や自前の割引計算などでキャッシュフロー表を組み立てられます(環境によってはパッケージのメンテナンス状況を確認し、代替として scipy やスプレッドシート連携を検討してください)。例えば、リボイラーの効率改善による年間利益増分から、投資の回収期間を定量化できます。
AI時代の統計処理
生成 AI や大規模言語モデル(LLM)の普及により、データ分析の入り口(コード生成、要約、仮説の列挙など)は大きく変わりつつあります。ただし、AI は探索や文章化には強い一方で、統計的妥当性の確認や再現可能な解析手順の担保は別問題です。そのため、AI を補助として用いながら、最終的な判断は検定・区間推定・感度分析など、従来型の統計解析で支える構成が望ましい場面が多いです。
今後は、自然言語でデータを扱うワークフローと、従来の統計解析をどのように接続するかが重要になります。その前提として、メタデータの整備、データ系譜(lineage)の追跡、品質検証ルールの自動化など、分析基盤側のガバナンスが中心になります。
当サイトの内容を実際のプラントの設計、運転、制御、および安全・経済性評価等に適用する場合は、必ず有資格の専門家によるレビューと実測データに基づく検証を行ってください。記述の利用により生じた損害について著者は一切の責任を負いかねます。免責の詳細はプライバシーポリシー・免責事項を参照してください。
不具合、ご意見等ございましたらCEsolutionにお知らせください。